《凤凰架构》
构建可靠的大型分布式系统
远程服务
远程的服务在哪里(服务发现),有多少个(负载均衡),网络出现分区、超时或者服务出错了怎么办(熔断、隔离、降级),方法的参数与返回结果如何表示(序列化协议),信息如何传输(传输协议),服务权限如何管理(认证、授权),如何保证通信安全(网络安全层),如何令调用不同机器的服务返回相同的结果(分布式数据一致性)等一系列问题,全都需要设计者耗费大量精力。
进程间通信:管道/具名管道、信号、信号量、消息队列、共享内存、本地套接字
RPC面向过程编程
REST只是一种风格,不是协议,REST的基本思想是面向资源来抽象问题
六大原则:客户端与服务端分离、无状态、可缓存、分层系统、统一接口、按需代码。
程度分级:完全不REST、开始引入资源概念、引入统一接口映射到HTTP协议的方法上、超媒体控制
解决REST问题的理论方案:GraphQL(更彻底的面向资源)
事务处理
事务问题A(原子性Atomic)C(一致性Consistency)I(隔离性Isolation)D(持久性Durability)
通过Commit Logging实现事务的原子性和持久性是当今的主流方案,还有另外一种称为“Shadow Paging”(有中文资料翻译为“影子分页”)的事务实现机制。阿里的OceanBase就是直接采用CommitLogging机制来实现事务的。Redo日志和Undo日志
解决隔离性:写锁、读锁、范围锁,不同的隔离级别对应三种锁的不同组合应用。
可串行化:对事务所有读、写的数据全都加上读锁、写锁和范围锁即可做到可串行化
可重复读(幻读问题):可重复读对事务所涉及的数据加读锁和写锁,且一直持有至事务结束,但不再加范围锁。但InnoDB在只读事务中可以完全避免幻读问题。
读已提交(不可重复读问题):读已提交对事务涉及的数据加的写锁会一直持续到事务结束,但加的读锁在查询操作完成后会马上释放。
读未提交(脏读问题):它只会对事务涉及的数据加写锁,且一直持续到事务结束,但完全不加读锁。
近年来有一种名为“多版本并发控制”(Multi-Version Concurrency Control,MVCC)的无锁优化方案被主流的商业数据库广泛采用。MVCC是一种读取优化策略,它的“无锁”特指读取时不需要加锁。
XA规范,早于java出现,对应JTA标准。XA将事务提交拆分成两阶段:
准备阶段:它与本地事务中真正提交的区别只是暂不写入最后一条Commit Record而已,这意味着在做完数据持久化后并不立即释放隔离性,即仍继续持有锁,维持数据对其他非事务内观察者的隔离状态。
提交阶段:对于数据库来说,这个阶段的提交操作应是很轻量的,仅仅是持久化一条Commit Record而已,通常能够快速完成,只有收到Abort指令时,才需要根据回滚日志清理已提交的数据,这可能是相对重负载操作。
“两段式提交”(2 Phase Commit,2PC)协议,而它能够成功保证一致性还需要一些其他前提条件。1、必须假设网络在提交阶段的短时间内是可靠的,即提交阶段不会丢失消息。2、必须假设因为网络分区、机器崩溃或者其他原因而导致失联的节点最终能够恢复,不会永久性地处于失联状态。
衍生出的”三阶段提交“:在事务需要回滚的场景中,三段式提交的性能通常要比两段式提交好很多,但在事务能够正常提交的场景中,两者的性能都很差,甚至三段式因为多了一次询问,还要稍微更差一些。
“FLP不可能原理”,证明了如果宕机最后不能恢复,那就不存在任何一种分布式协议可以正确地达成一致性结果。该原理在分布式中是与CAP不可兼得原理齐名的理论。
麻省理工学院的Seth Gilbert和Nancy Lynch以严谨的数学推理证明了CAP猜想。Consistency、Availability、Partition Tolerance
HBase属于CP系统
选择放弃一致性的AP系统是目前设计分布式系统的主流选择
通过最终一致性来解决实际问题。BASE分别是基本可用性(Basically Available)、柔性事务(Soft State)和最终一致性(EventuallyConsistent)的缩写。
可靠事件队列(消息队列事务):最容易出错的动作应该最先进行,消息都必须具备幂等性。只要第一步业务完成了,后续就没有失败回滚的概念,只许成功,不许失败。问题是没有隔离性,会产生超售的问题。
“最大努力交付”(Best-Effort Delivery),譬如TCP协议中未收到ACK应答自动重新发包的可靠性保障就属于最大努力交付。
TCC(Try-Confirm-Cancel)事务,·Try:尝试执行阶段,完成所有业务可执行性的检查(保障一致性),并且预留好全部需要用到的业务资源(保障隔离性)。·Confirm:确认执行阶段,不进行任何业务检查,直接使用Try阶段准备的资源来完成业务处理。Confirm阶段可能会重复执行,因此本阶段执行的操作需要具备幂等性。·Cancel:取消执行阶段,释放Try阶段预留的业务资源。Cancel阶段可能会重复执行,因此本阶段执行的操作也需要具备幂等性。
TCC具有很高的性能潜力,也带来了更高的开发成本和业务侵入性,即更高的开发成本和更换事务实现方案的替换成本。阿里开源的Seata。
SAGA事务。SAGA在英文中是“长篇故事、长篇记叙、一长串事件”的意思。将大事务拆分成若干个小事务,将整个分布式事务T分解为n个子事务,命名为T1,T2,…,Ti,…,Tn。与TCC相比,SAGA不需要为资源设计冻结状态和撤销冻结的操作,补偿操作往往要比冻结操作容易实现得多。SAGA必须保证所有子事务都得以提交或者补偿,但SAGA系统本身也有可能会崩溃,所以它必须设计成与数据库类似的日志机制(被称为SAGA Log)以保证系统恢复后可以追踪到子事务的执行情况。Seata同样支持SAGA事务模式。
阿里的GTS(GlobalTransaction Service,Seata由GTS开源而来)所提出的“AT事务模式”,参照了XA两段提交协议实现的,但对于XA 2PC的缺陷设计了针对性的解决方案。
多级分流系统
作为系统的设计者,我们应该意识到不同的设施、部件在系统中有各自不同的价值。
有一些部件位于客户端或网络的边缘,能够迅速响应用户的请求,避免给后方的I/O与CPU带来压力,典型如本地缓存、内容分发网络、反向代理等。
有一些部件的处理能力能够线性拓展,易于伸缩,可以使用较小的代价堆叠机器来获得与用户数量相匹配的并发性能,应尽量作为业务逻辑的主要载体,典型如集群中能够自动扩缩的服务节点。
有一些部件稳定服务对系统运行有全局性的影响,要时刻保持容错备份,维护高可用性,典型如服务注册中心、配置中心。
有一些设施是天生的单点部件,只能依靠升级机器本身的网络、存储和运算性能来提升处理能力,如位于系统入口的路由、网关或者负载均衡器。
对系统进行流量规划时,我们应该充分理解这些部件的价值差异,有两条简单、普适的原则能指导我们进行设计。
第一条原则是尽可能减少单点部件。另一条更关键的原则是奥卡姆剃刀原则。在能满足需求的前提下,最简单的系统就是最好的系统。
客户端缓存
强制缓存:基于时效性,HTTP1.0的Expires、HTTP1.1的Cache-Control
协商缓存:基于变化检测,Last-Modified,304/Not Modified
世界根域名服务器的ZONE文件只有2MB大小,甚至可以打印出来物理备份。
首先DNS会将域名还原为“www.icyfenix.cn.”,注意最后多了一个点“.”,它是“.root”的含义。
1、客户端先检查本地的DNS缓存(TTL存活时间)
2、客户端将地址发送给本机操作系统中配置的本地DNS(Local DNS),这个本地DNS服务器可以由用户手工设置,也可以在DHCP分配或者拨号时从PPP服务器中自动获取到。
3、本地DNS收到查询请求后,会按照“是否有www.icyfenix.com.cn的权威服务器”→“是否有icyfenix.com.cn的权威服务器”→“是否有com.cn的权威服务器”→“是否有cn的权威服务器”的顺序,依次查询自己的地址记录,如果都没有查询到,就会一直找到最后点号代表的根域名服务器为止。这个步骤里涉及两个重要名词。
4、现在假设本地DNS是全新的,上面不存在任何域名的权威服务器记录,所以当DNS查询请求按步骤3的顺序一直查到根域名服务器之后,它将会得到“cn的权威服务器”的地址记录,然后通过“cn的权威服务器”,得到“com.cn的权威服务器”的地址记录,以此类推,最后找到能够解释“www.icyfenix.com.cn”的权威服务器地址。
- 权威域名服务器(Authoritative DNS):负责翻译特定域名的DNS服务器,“权威”意味着域名应该翻译出怎样的结果是由这个服务器决定的。DNS翻译域名时无须像查电话本一样刻板地一对一翻译,根据来访机器、网络链路、服务内容等各种信息,可以玩出很多花样。权威DNS的灵活应用,在后面的内容分发网络、服务发现等章节还会有所涉及。
- 根域名服务器(Root DNS):固定的、无须查询的顶级域名(Top-LevelDomain)服务器,可以默认它们已内置在操作系统代码之中。全世界一共有13组根域名服务器(注意并不是13台),每一组根域名都通过任播(Anycast)的方式建立了一大群镜像,根据维基百科的数据,迄今已经超过1000台根域名服务器的镜像了。选择13是由于DNS主要采用UDP传输协议(在需要稳定性保证的时候也可以采用TCP)来进行数据交换,未分片的UDP数据包在IPv4下的最大有效值为512字节,最多可以存放13组地址记录。
DNS的设计可能受到中间人攻击的威胁,产生被劫持的风险。HTTPDNS可以防止
传输链路的三个问题:缓存、连接、压缩
TCP还有慢启动的特性,使得刚刚建立连接时的传输速度是最低的,后面再逐步加速直至稳定。由于TCP协议本身是面向长时间、大数据传输来设计的,在长时间尺度下,它建立连接的高昂成本才不至于成为瓶颈,它的稳定性和可靠性的优势才能展现出来。
Keep-Alive机制的副作用是“队首阻塞”(Head-of-Line Blocking)问题。HTTP/2多路复用(HTTP/2 Multiplexing)技术解决了该问题。在HTTP/1.x中,HTTP请求就是传输过程中最小粒度的信息单位了。而在HTTP/2中,帧(Frame)才是最小粒度的信息单位。不需要突破浏览器对每个域名最多6个的连接数限制。
与HTTP/1.x相比,HTTP/2本身变得更适合传输小资源,譬如传输1000张10KB的小图,HTTP/2肯定要比HTTP/1.x快,但传输10张1000KB的大图,则大概率HTTP/1.x会更快些。这是TCP连接数量(相当于多点下载)的影响,但更多是由TCP协议可靠传输机制导致的,一个错误的TCP包会导致所有的流都必须等待这个包重传成功,这是HTTP/3要解决的问题。因此,把小文件合并成大文件,在HTTP/2下是毫无益处的。
HTTP/1.1版本中增加了另一种“分块传输编码”(ChunkedTransfer Encoding)的资源结束判断机制,彻底解决了Content-Length与持久连接时资源即时压缩的冲突问题。
HTTP3(基于Quick UDP Internet Connection,QUIC)设计重点是替换TCP传输协议。针对移动场景,QUIC提出了连接标识符的概念,该标识符可以唯一地标识客户端与服务器之间的连接,而无须依靠IP地址。这样,切换网络后,只需向服务端发送一个包含此标识符的数据包即可重用既有的连接,因为即使用户的IP地址发生变化,原始连接的连接标识符依然是有效的。
内容分发网络(CDN)的工作过程,主要涉及路由解析、内容分发、负载均衡和CDN应用四个方面。CDN获取源站资源的过程被称为“内容分发”,目前主要有以下两种主流的内容分发方式。主动分发(Push)、被动回源(Pull)。
CDN作用:加速静态资源分发、安全防御、协议升级、状态缓存、修改资源、访问控制、注入功能。
负载均衡,四层负载均衡的优势是性能高,七层负载均衡的优势是功能强。做多级混合负载均衡,通常应是低层负载均衡在前,高层负载均衡在后。三角传输模式、代理模式
第二层数据链路层传输的内容是数据帧(Frame),如1500字节MTU的以太网帧,其中包含了源和目标MAC地址,数据链路层负载均衡所做的工作,是修改请求的数据帧中的MAC目标地址,让用户原本发送给负载均衡器的请求的数据帧,被二层交换机根据新的MAC目标地址转发到服务器集群中对应的真实服务器的网卡上,这样真实服务器就获得了一个原本目标并不是发送给它的数据帧。必须保证所有的真实服务器与负载均衡器有相同的虚拟IP地址
第三层网络层传输的单位是分组数据包(Packet),这是一种在分组交换网络(Packet Switching Network,PSN)中传输的结构化数据单位。IP分组数据包的Header中带有源和目标的IP地址。IP隧道模式,新创建一个数据包,把原数据包的Header和Payload整体作为新数据包的Payload,并在这个新数据包的Header中写入真实服务器的IP作为目标地址。同样必须保证所有的真实服务器与负载均衡器有相同的虚拟IP地址。另一种NAT模式会带来带宽资源竞争问题(也就是我们常见的路由器)。
工作在四层之后的负载均衡模式就无法再转发了,只能代理,此时真实服务器、负载均衡器、客户端三者之间由两条独立的TCP通道来维持通信。根据“哪一方能感知到”的原则,可以分为“正向代理”“反向代理”和“透明代理”三类。
均衡策略:轮询、权重轮询、随机、权重随机、一致性哈希、响应速度、最少连接数。
软件负载均衡:系统内核如LVS,应用程序如Nginx,HAProxy,KeepAlived
硬件负载均衡:F5,A10
引入缓存带来的问题:开发角度,提高系统复杂度、运维角度,缓存会掩盖一些缺陷、安全角度,缓存可能会泄漏某些保密数据,也是容易受到攻击的薄弱点。
缓存的目的:为缓解CPU压力而引入缓存、为缓解I/O压力而引入缓存。缓存虽然是典型以空间换时间来提升性能的手段,但它的出发点是缓解CPU和I/O资源在峰值流量下的压力,“顺带”而非“专门”地提升响应性能。
设计缓存考虑维度:吞吐量、命中率、扩展功能、分布式缓存
进程缓存:Caffeine、ConcurrentLinkedHashMap、LinkedHashMap、Guava Cache、Ehcache和Infinispan Embedde(性能由高到低)
GuavaCache为代表的同步处理机制,即在访问数据时一并完成缓存淘汰、统计、失效等状态变更操作,通过分段加锁等优化手段来尽量减少竞争。
以Caffeine为代表的异步日志提交机制,这种机制参考了经典的数据库设计理论,将数据的读、写过程看作日志(即对数据的操作指令)的提交过程。在Caffeine的实现中,每个线程都设有专门的环形缓存区(Ring Buffer,也常称作CircularBuffer)来记录由于数据读取而产生的状态变动日志。从Caffeine读取数据时,数据本身会在其内部的ConcurrentHashMap中直接返回,而数据的状态信息变更就存入环形缓冲中,由后台线程异步处理。向Caffeine写入数据时,将使用传统的有界队列(ArrayQueue)来存放状态变更信息,写入带来的状态变更是无损的,不允许丢失任何状态。
缓存淘汰策略:FIFO、LRU、LFU、TinyLFU、W-TinyLFU
分布式缓存:大对象中修改一个值问题的性能问题,一致性问题(通常使用AP模式)
缓存穿透,有可能是业务逻辑本身就存在的固有问题,也有可能是恶意攻击所导致。为了解决缓存穿透问题,通常会采取下面两种办法。缓存空值,布隆过滤器判断key是否存在。
缓存击穿,热点数据失效导致,加锁或手动管理缓存
缓存雪崩,随机失效时间,多级缓存
缓存污染,Cache Aside模式
架构安全
LDAP、OAuth2、JWT、摘要、加密、签名
Hash代替明文
密码加盐防止彩虹表攻击
动态盐值防止冒认
动态令牌可以防止重放攻击
HTTPS可以防止链路上的恶意嗅探
独立物理设备、独立信息通道、专用网络
中间人攻击
加密基础是大素数的乘机做质因数分解,然而如何对大数进行质因数分解,迄今还没有找到多项式时间的算法,甚至无法确切地知道这个问题属于哪个复杂度类(ComplexityClass)。所以尽管这个过程在理论上一定是可逆的,但实际上算力差异决定了逆过程无法实现。
对称加密算法,密钥数量问题、密钥分发问题
非对称加密算法,解决密钥分发问题,但由于计算复杂度高,性能要差好几个数量级。不支持分组,所以主流算法都只能加密不超过秘钥长度的数据,不能用于大量数据的加密。
公钥加密+私钥解密,内容不会被读取也不能被篡改
私钥加密+公钥解密,用于签名,可以防止篡改,但不能保证不被获取
保证公钥可信分发的标准,即公开密钥基础设施(Public Key Infrastructure,PKI)。在密码学中,公开密钥基础建设借着数字证书认证中心(Certificate Authority,CA)将用户的个人身份跟公开密钥链接在一起,且每个证书中心用户的身份必须是唯一的。PKI的确定链接关系的这一角色称为注册管理中心(Registration Authority,RA)。RA确保公开密钥和个人身份链接,可以防抵赖。证书(Certificate)是权威CA中心对特定公钥信息的一种公证载体。
传输安全层(Transport Layer Security)当前主流版本TLS1.2,两轮四次握手:client hello - server hello - client handshake finished - server handshake finished
分布式理论
“分布式一致性算法”这个翻译不准确,其指的其实是“Distributed Consensus Algorithm”,应该翻译为“分布式共识算法”。其基础是计算机科学中的状态机。
世界上只有一种共识协议,就是Paxos,其他所有共识算法都是Paxos的退化版本。Paxos是一种基于消息传递的协商共识算法,是当今分布式系统最重要的理论基础,几乎就是“共识”二字的代名词。Paxos算法并不考虑拜占庭将军问题,即假设信息可能丢失也可能延迟,但不会被错误传递。
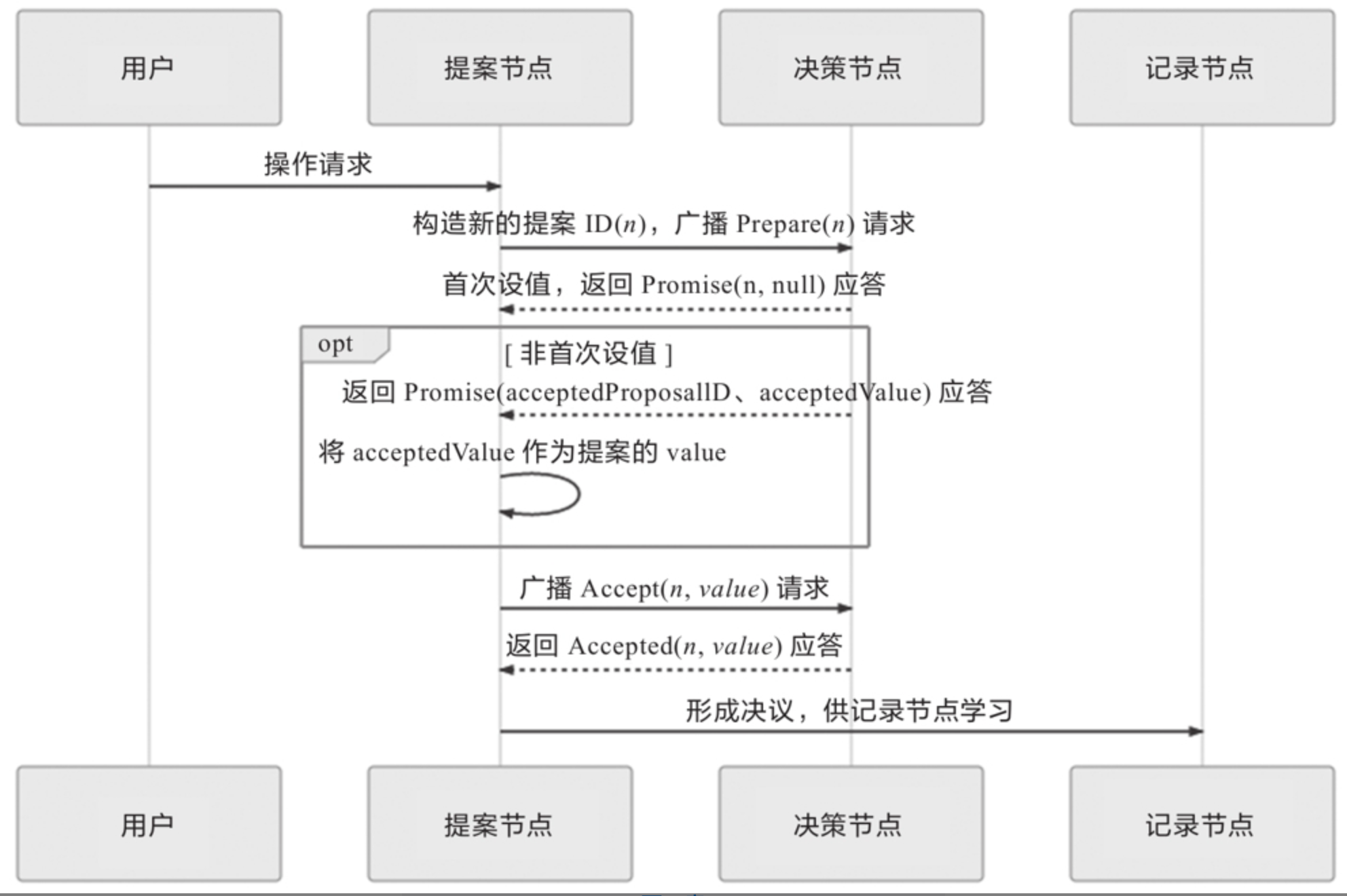
Paxos算法将分布式系统中的节点分为三类。
- 提案节点:称为Proposer,提出对某个值进行设置操作的节点,设置值这个行为就被称为提案(Proposal),值一旦设置成功,就是不会丢失也不可变的。后面介绍的Raft算法中就直接把“提案”叫作“日志”了。
- 决策节点:称为Acceptor,是应答提案的节点,决定该提案是否可被投票、是否可被接受。提案一旦得到过半数决策节点的接受,即称该提案被批准(Accept)。提案被批准即意味着该值不能被更改,也不会丢失,且最终所有节点都会接受它。
- 记录节点:称为Learner,不参与提案,也不参与决策,只是单纯地从提案、决策节点中学习已经达成共识的提案,譬如少数派节点从网络分区中恢复时,将会进入这种状态。
在使用Paxos算法的分布式系统里,所有的节点都是平等的,它们都可以承担以上某一种或者多种的角色,不过为了便于确保有明确的多数派,决策节点的数量应该被设定为奇数个,且在系统初始化时,网络中每个节点都应该知道整个网络所有决策节点的数量、地址等信息。
决策节点:
承诺不会再接受提案ID小于或等于n的Prepare请求;
承诺不会再接受提案ID小于n的Accept请求。
在不违背以前的承诺的前提下,回复已经批准过的提案中ID最大的那个提案所设定的值和提案ID,如果该值从来没有被任何提案设定过,则返回空值。如果违反此前做出的承诺,即收到的提案ID并不是决策节点收到的最大的ID,那允许直接对此Prepare请求不予理会。
prepare-promise-accept-accepted
Basic Paxos、Multi Paxos、Fast Paxos、Raft、ZAB。
Multi Paxos对Basic Paxos的核心改进是增加了“选主”的过程。把共识问题分解为“选主”、“复制”和“安全”三个问题来思考、解决的思路,即“Raft算法”(在Raft的《一种可以让人理解的共识算法》中提出),并获得了USENIX ATC 2014大会的Best Paper,后来更是成为etcd、LogCabin、Consul等重要分布式程序的实现基础,ZooKeeper的ZAB算法与Raft的思路也非常类似,这些算法都被认为是Multi Paxos的等价派生实现。
“最终一致性”的分布式共识协议:Gossip协议。相比Paxos、Raft等算法,Gossip的过程十分简单,它可以看作以下两个步骤的简单循环。相比Paxos、Raft等算法,Gossip的过程十分简单,它可以看作以下两个步骤的简单循环。1、如果有某一项信息需要在整个网络的所有节点中传播,那从信息源开始,选择一个固定的传播周期(譬如1秒),随机选择它相连接的k个节点(称为Fan-Out)来传播消息。2、每一个节点收到消息后,如果这个消息是它之前没有收到过的,则在下一个周期内,该节点将向除了发送消息给它的那个节点外的其他相邻的k个节点发送相同的消息,直到最终网络中所有节点都收到了消息。尽管这个过程需要一定时间,但是理论上最终网络的所有节点都会拥有相同的消息。
微服务
服务发现,Eureka是AP,Consul是CP基于Raft算法,ZK基于ZAP算法,etcd基于Raft算法,同时支持CP和AP的Nacos,k8s使用CoreDNS
网关路由,网关=路由器(基础职能)+过滤器(可选职能)。基于Nginx、HAProxy开发的Ingress Controller(k8s组件),基于Netty开发的Zuul 2.0等
客户端负载均衡,Ribbon,LoadBalancer。代理客户端负载均衡,网格服务的Pod sidecar内
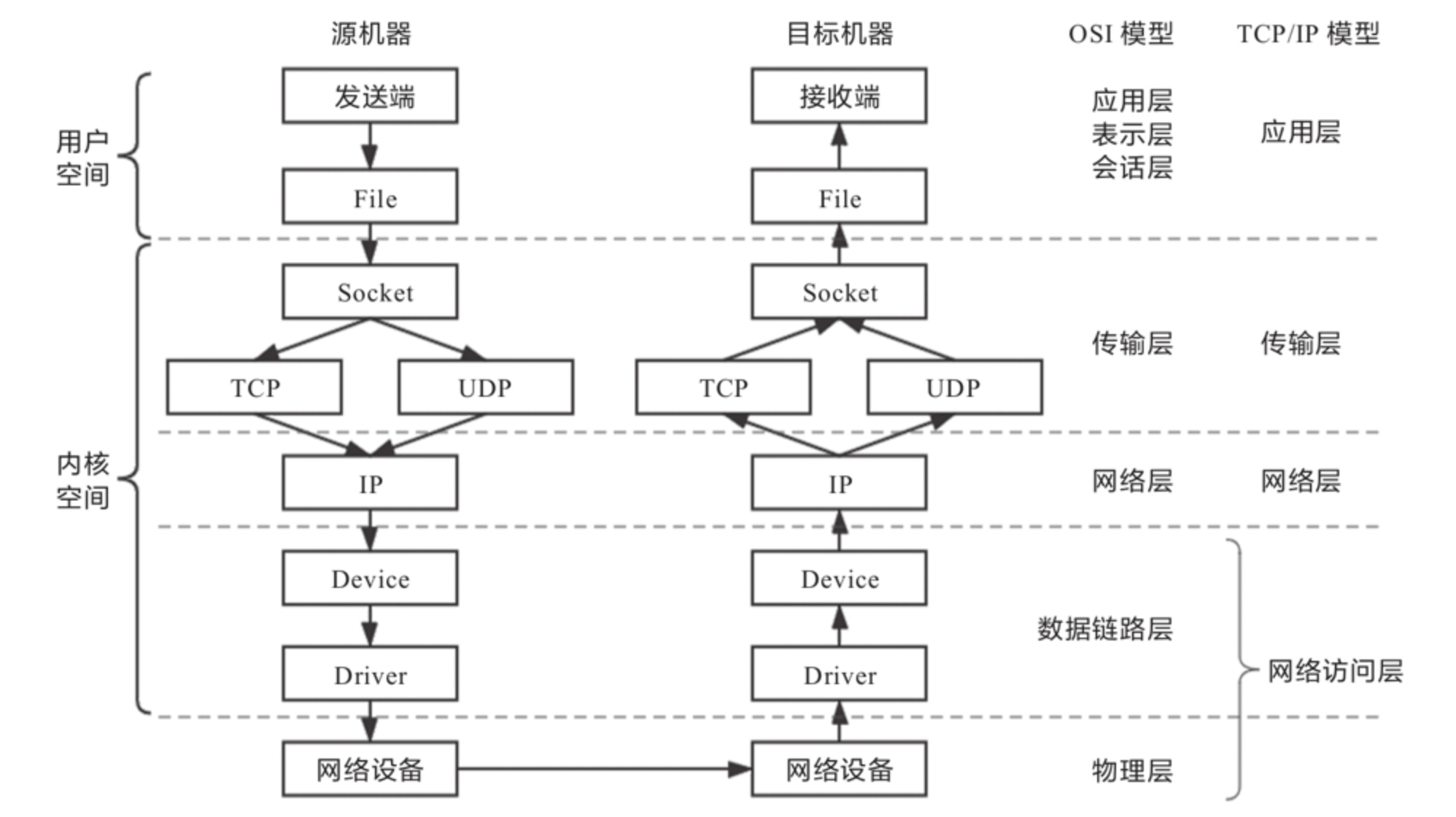
网络I/O模型,Socket在操作系统接口中被抽象为数据流,而网络I/O可以理解为对流的操作。一次网络访问:远程主机返回的数据→存放到操作系统内核缓冲区→复制到应用程序的地址空。
两类、五种模型:两类是指同步I/O与异步I/O,五种是指在同步I/O中又划分出阻塞I/O、非阻塞I/O、多路复用I/O、信号驱动I/O四种细分模型以及异步I/O模型。在Linux系统下实现高并发网络编程时仍以多路复用I/O模型模式为主。
Region是地域的意思,面向全球或全国的大型系统的服务集群往往会部署在多个不同地域,大型系统就是通过不同地域的机房来缩短用户与服务器之间的物理距离,以提升响应速度,对于小型系统,地域一般就只在异地容灾时才会涉及。需要注意,不同地域之间是没有内网连接的。所以集群内部流量是不会跨地域的,服务发现、负载均衡器默认也是不会支持跨地域的服务发现和负载均衡的。
Zone是区域的意思,它是可用区域(Availability Zone)的简称。区域指在地理上位于同一地域内,但电力和网络是互相独立的物理区域,譬如在华东的上海、杭州、苏州的不同机房就是同一个地域的几个可用区域。同一个地域的可用区域之间具有内网连接,流量不占用公网带宽,因此区域是微服务集群内流量能够触及的最大范围。
异地容灾和异地双活的差别:容灾是非实时的同步,而双活是实时或者准实时的,跨地域或者跨区域做容灾都可以,但一般只能跨区域做双活,当然,也可以将它们结合起来使用,即“两地三中心”模式。
流量治理
问题:一个服务崩溃引发雪崩效应,突发流量导致服务阻塞
信息系统设计成分布式架构的主要动力之一就是为了提升系统的可用性,最低限度也必须保证将原有系统重构为分布式架构之后,可用性不下降才行。
容错策略:故障转移(Failover)、快速失败(Failfast)、安全失败(Failsafe)、沉默失败(Failsilent)、故障恢复(Failback)
容错设计模式:断路器模式(服务熔断和服务降级)、舱壁隔离模式(服务隔离,如线程池隔离和信号量机制)、重试模式(仅对主路中的关键服务做同步重试,要求幂等性)
流量控制(限流),依据什么限流,具体如何限流,超额流量如何处理。
流量指标,TPS(每秒事务数)、HPS(每秒请求数)、QPS(每秒查询数)
限流设计模式:流量计数器模式、滑动时间窗模式、漏桶模式、令牌桶模式
分布式限流,令牌桶优化为额度。限流与容错不一样,做分布式限流从不追求“越彻底越好”,往往需要权衡方案付出的代价与得到的收益。
可靠通信
边界安全模型,着重对经过网络区域边界的流量进行检查,对可信任区域(内网)内部机器之间的流量则给予直接信任或者较为宽松的处理策略,减小了安全设施对整个应用系统复杂度的影响以及网络传输性能的额外损耗。
零信任安全模型,中心思想是不应当以某种固有特征来自动信任任何流量,除非明确得到了能代表请求来源(不一定是人,更可能是另一台服务器)的身份凭证,否则一律不会有默认的信任关系。
可观测性
事件日志、链路追踪和聚合度量三个方向。
日志,elk,logstash,Filebeat
追踪,zipkin,pinpoint,skywalking,鹰眼
度量,Prometheus,zabbix,时序数据库influxdb
监控预警
从这一章的内容来看,互客的可观测性做的不错。
虚拟化容器
ISA(Instruction Set Architecture,指令集架构)是计算机体系结构中与程序设计相关的部分,包含基本数据类型、指令集、寄存器、寻址模式、存储体系、中断、异常处理以及外部I/O。
ABI(Application Binary Interface,应用二进制接口)是应用程序与操作系统之间或其他依赖库之间的低级接口。
根据抽象目标与兼容性高低的不同,虚拟化技术又分为下列五类。
- 指令集虚拟化(ISA Level Virtualization),就是仿真,性能损失最大。
- 硬件抽象层虚拟化(Hardware Abstraction Level Virtualization),如VMware、Hyper-V,一般说的虚拟机就是指这一类。
- 操作系统层虚拟化(OS Level Virtualization),不会提供真实的操作系统,而是采用隔离手段,使得不同进程拥有独立的系统资源和资源配额,看起来仿佛是独享了整个操作系统,但其实系统的内核仍然是被不同进程所共享的。也就是“容器化”
容器化牺牲了一定的隔离性与兼容性,换来的是比前两种虚拟化更高的启动速度、运行性能和更低的执行负担。
隔离文件:chroot、隔离访问:Namespace、隔离资源:cgroups、封装系统:LXC、封装应用:Docker、封装集群:kubernetes
2014年,Docker开源了自己用Go语言开发的libcontainer。这是一个越过LXC直接操作namespaces和cgroups的核心模块,它使得Docker能直接与系统内核打交道,而不必依赖LXC来提供容器化隔离能力。2015年,在Docker的主导和倡议下,多家公司联合制定了“开放容器交互标准”(Open Container Initiative,OCI),将libcontainer独立出来,封装重构成runC项目,并捐献给Linux基金会管理。重构了Docker Daemon子系统,将其中与运行时交互的部分抽象为containerd项目。
Kubernetes Master→kubelet→DockerManager→DockerEngine→containerd→runC
KubernetesMaster→kubelet→KubeGenericRuntimeManager→DockerShim→DockerEngine→containerd→runC
KubernetesMaster→kubelet→KubeGenericRuntimeManager→containerd→runC
容器的本质是对cgroups和namespaces所提供的隔离能力的一种封装,在Docker提倡的单进程封装的理念影响下,容器蕴含的隔离性多了仅针对单个进程的额外限制,而Linux的cgroups和namespaces原本都是针对进程组而非单个进程来设计的,同一个进程组中的多个进程天然就可以共享相同的访问权限与资源配额。如果现在我们把容器与进程在概念上对应起来,那容器编排的第一个扩展点,就是要找到容器领域中与“进程组”相对应的概念,这是实现容器从隔离到协作的第一步,在Kubernetes的设计里,这个对应物叫作Pod。扮演容器组的角色,满足容器共享名称空间的需求,是Pod的两大最基本职责之一,同处于一个Pod内的多个容器,相互之间以超亲密的方式协作。它们将默认共享如下内容:
- UTS名称空间:所有容器都有相同的主机名和域名。
- 网络名称空间:所有容器都共享一样的网卡、网络栈、IP地址等。因此,同一个Pod中不同容器占用的端口不能冲突。
- IPC名称空间:所有容器都可以通过信号量或者POSIX共享内存等方式通信。
- 时间名称空间:所有容器都共享相同的系统时间。
同一个Pod的容器,只有PID名称空间和文件名称空间默认是隔离的。可以通过Pod元数据定义中的spec.shareProcessNamespace来改变。容器间可以共享存储卷,这是通过Kubernetes的Volume来实现的。
Pod的另外一个基本职责是实现原子性调度。Pod是隔离与调度的基本单位,也是我们接触的第一种Kubernetes资源。Kubernetes将一切皆视为资源,不同资源之间依靠层级关系相互组合、协作的这个思想是贯穿Kubernetes整个系统的两大核心设计理念之一,不仅在容器、Pod、主机、集群等计算资源上是这样,在工作负载、持久存储、网络策略、身份权限等其他领域中也都有一致的体现。
k8s的两大核心设计理念:资源模型和控制器模式。工业领域的”控制回路“。
通过描述清楚这些资源的期望状态,由Kubernetes中对应监视这些资源的控制器来驱动资源的实际状态逐渐向期望状态靠拢。这种交互风格被称为Kubernetes的声明式API,日常在元数据文件中定义的spec字段所描述的便是资源的期望状态。
ReplicaSet也是一种资源,属于工作负荷类,代表一个或多个Pod副本的集合。可以保证Pod出现故障时自动恢复。由Deployment来创建ReplicaSet,再由ReplicaSet来创建Pod,当你更新Deployment中的信息(譬如更新了镜像的版本)后,部署控制器就会跟踪到新的期望状态,自动创建新的ReplicaSet,并逐渐缩减旧的ReplicaSet的数量,直至升级完成后彻底删除掉旧的ReplicaSet。Kubernetes又提供了Autoscaling资源和自动扩缩控制器,从而自动根据度量指标,如处理器、内存占用率、用户自定义的度量值等,来设置Deployment(或者ReplicaSet)的期望状态,实现当度量指标出现变化时,系统自动按照“Autoscaling→Deployment→ReplicaSet→Pod”这样的顺序层层变更,最终实现根据度量指标自动扩容/缩容。
Helm一开始的目标就很明确:如果说Kubernetes是云原生操作系统,那Helm就要成为这个操作系统上的应用商店与包管理工具。
Operator是使用自定义资源(CR,Custom Resource,是CRD的实例),管理应用及其组件的自定义Kubernetes控制器。将简洁的高级指令转化为Kubernetes中具体操作的方法,与前面Helm或者Kustomize的方法并不相同。Helm和Kustomize最终仍然是依靠Kubernetes的内置资源来跟Kubernetes打交道的,Operator则要求开发者自己实现一个专门针对该自定义资源的控制器,在控制器中维护自定义资源的期望状态。
最后一种应用封装的方案,是阿里云和微软公司在2019年10月上海QCon大会上联合发布的开放应用模型(Open Application Model,OAM),它不仅是中国云计算企业参与制定乃至主导发起的国际技术规范,也是业界首个云原生应用标准定义与架构模型。
容器间网络
在Linux目前提供的八种名称空间里,网络名称空间无疑是隔离内容最多的一种,它为名称空间内的所有进程提供了全套的网络设施,包括独立的设备界面、路由表、ARP表,IP地址表、iptables/ebtables规则、协议栈,等等。
网络栈中的数据流动的路径:
目前主流的虚拟网卡方案有tun/tap和veth两种。
tun和tap是两个相对独立的虚拟网络设备,其中tap模拟了以太网设备,操作二层数据包(以太帧),tun则模拟了网络层设备,操作三层数据包(IP报文)。使用tun/tap设备的目的是实现把来自协议栈的数据包先交由某个打开了/dev/net/tun字符设备的用户进程处理后,再把数据包重新发回到链路中。
veth(虚拟以太网,Virtual Ethernet)实际上不是一个设备,而是一对设备,因而也常被称作veth pair。要使用veth,必须在两个独立的网络名称空间中进行才有意义,因为veth pair是一端连着协议栈,另一端彼此相连的。
虚拟交换机Linux Bridge。
Docker三种网络方案:桥接模式(默认,veth,docker0网桥,通过二层网络通信)、主机模式(直接使用宿主机)、空置模式。
可以用户自行创建的网络:容器模式、MACVLAN模式、Overlay模式。
kubenet是kubelet内置的一个非常简单的网络,它采用网桥来实现Pod间通信。
容器的持久化存储
Docker内置了三种挂载类型,分别是Bind(–mount type=bind)、Volume(–mount type=volume)和tmpfs(–mount type=tmpfs)。Kubernetes同样将操作系统和Docker的Volume概念延续了下来,并对其进行了细化。Kubernetes将Volume分为持久化的PersistentVolume和非持久化的普通Volume两类。
PersistentVolume是由管理员负责提供的集群存储。
PersistentVolumeClaim是由用户负责提供的存储请求。
1、管理员准备好要使用的存储系统,它应是某种网络文件系统(NFS)或者云储存系统,一般来说应该具备跨主机共享的能力。2、管理员根据存储系统的实际情况手工预先分配好若干个PersistentVolume,并定义好每个PersistentVolume可以提供的具体能力。3、用户根据业务系统的实际情况创建PersistentVolumeClaim,声明Pod运行所需的存储能力。4、Kubernetes在创建Pod的过程中,会根据系统中PersistentVolume与Persistent-VolumeClaim的供需关系对两者进行撮合。如果系统中存在满足PersistentVolumeClaim声明中要求能力的PersistentVolume,则撮合成功,将它们绑定。如果撮合不成功,Pod就不会被继续创建,直至系统中出现新的或让出空闲的PersistentVolume资源。
Kubernetes的存储插件:In-Tree、Out-of-Tree
Kubernetes目前同时支持FlexVolume与CSI(Container Storage Interface,容器存储接口)两套独立的存储扩展机制。
容器编排(资源与调度)
“一切皆为资源”的设计是Kubernetes能够顺利施行声明式API的必要前提。Kubernetes以资源为载体,建立了一套同时囊括抽象元素(如策略、依赖、权限)和物理元素(如软件、硬件、网络)的领域特定语言。
从编排系统的角度来看,Node是资源的提供者,Pod是资源的使用者,调度是对两者进行恰当的撮合。
Kubernetes目前提供的服务质量等级一共分为三级,由高到低分别为Guaranteed、Burstable和BestEffort。如果Pod中所有的容器都设置了limits和requests,且两者的值相等,那此Pod的服务质量等级便为最高的Guaranteed;如果Pod中有部分容器的requests值小于limits值,或者只设置了requests而未设置limits,那此Pod的服务质量等级为第二级Burstable;如果是上文说的那种情况,limits和requests两个都没设置则属于最低的BestEffort。
Pod的驱逐机制是通过kubelet来执行的,kubelet是部署在每个节点的集群管理程序,由于本身就运行在节点中,所以最容易感知到节点的资源实时消耗情况。kubelet一旦发现某种不可压缩资源将要耗尽时,就会主动终止节点上较低服务质量等级的Pod,以保证其他更重要的Pod的安全。被驱逐的Pod中的所有容器都会被终止,Pod的状态也会被更改为Failed。
服务网格(Service Mesh)
容器编排系统管理的最细粒度只能到达容器层次,在此粒度之下的技术细节,仍然只能依赖程序员自己来管理,编排系统很难提供有效的支持。服务网格之所以能够获得企业与社区的重视,是因为它很好地弥补了容器编排系统对分布式应用细粒度管控能力不足的缺憾。
服务网格是一种用于管控服务间通信的基础设施,职责是支持现代云原生应用网络请求在复杂拓扑环境中的可靠传递。在实践中,服务网格通常会以轻量化网络代理的形式来体现,这些代理与应用程序代码会部署在一起,对应用程序来说,它完全不会感知到代理的存在。——透明通信的实现希望
从总体架构看,服务网格包括两大块内容,分别是由一系列与微服务共同部署的边车代理,以及用于控制这些代理的管理器所构成。代理与代理之间需要通信,用以转发程序间通信的数据包;代理与管理器之间也需要通信,用以传递路由管理、服务发现、数据遥测等控制信息。服务网格使用数据平面(Data Plane)通信和控制平面(Control Plane)通信来形容这两类流量。在工业界,数据平面已有Linkerd、Nginx、Envoy等产品,控制平面也有Istio、Open Service Mesh、Consul等产品。
微服务理论
IBM大型机之父Fred Brooks在他的两本著作《没有银弹:软件工程的本质性与附属性工作》和《人月神话:软件项目管理之道》里都反复强调一个观点:“软件研发中任何一项技术、方法、架构都不可能是银弹。”这个结论已经被软件工程里无数事实所验证,现在对于微服务也依然成立。
为何选择微服务:为异构能力进行的分布式部署,并不是你想或者不想的问题,而是没有选择、不可避免的。保证系统整体的稳定和局部的容错、自愈与快速迭代。让系统有更好的可观测性和回弹性(自愈能力)。
微服务最主要的目的是对系统进行有效拆分,实现物理层面的隔离,微服务的核心价值就是拆分之后的系统能够让局部的单个服务有可能实现敏捷地卸载、部署、开发、升级,而局部的持续更迭,是系统整体具备Phoenix特性的必要条件。
设计系统的架构受制于产生这些设计的组织的沟通结构。(Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.)——Melvin Conway,康威定律,1968年
长期来看,多数服务的结局都是报废而非演进。——Martin Fowle
微服务的前提:决策者与执行者都能意识到康威定律在软件设计中的关键作用。组织中具备一些对微服务有充分理解、有一定实践经验的技术专家。系统应具有以自治为目标的自动化与监控度量能力。复杂性已经成为制约生产力的主要矛盾。
“识别微服务的边界”其实已取得了较为一致的观点,也找到了指导具体实践的方法论,即领域驱动设计(Domain-Driven Design,DDD)。
微服务粒度的下界是它至少应满足独立——能够独立发布、独立部署、独立运行与独立测试,内聚——强相关的功能与数据在同一个服务中处理,完备——一个服务包含至少一项业务实体与对应的完整操作。
微服务粒度的上界是一个2 Pizza Team能够在一个研发周期内完成的全部需求范围。
治理就是让产品能够符合预期地稳定运行,并能够持续保持在一定的质量水平上。——Magic Quadrant for SOA Governance,Gartner,2007年